

Table of contents
This is a run down on the basic multi-tenant SaaS data model underlying Checkly. Users, accounts, plans, that type of stuff. When building this, I found it surprisingly hard to find any solid info in the gazillions of developer and startup blogs; most were just to vague on the implementation details.
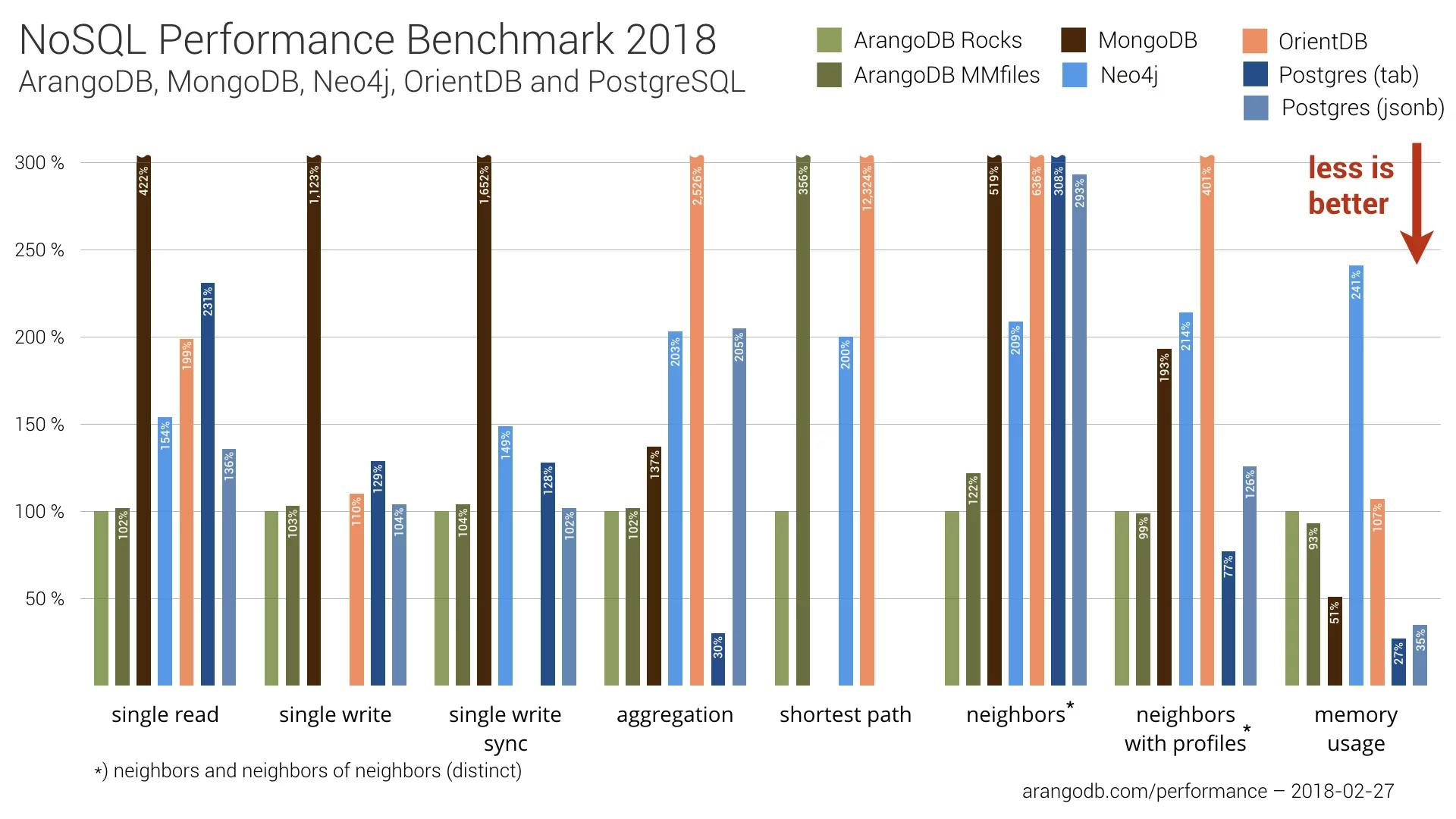
PostgreSQL, Mongo or DynamoDB?
Short version: Postgres. It's an absolutely fantastic piece of engineering.
Run it on Heroku, it just works™ and it makes me feel like some grizzled, elite Spetsnatz commando has my back.
Long version: In an alternative universe, I'd have implemented Checkly completely on AWS DynamoDB. The peace of mind a fully managed — web scale... — database brings you is just awesome when you want to focus on customers instead of database management.
So I actually tried getting a SaaS model into DynamoDB. That exercise was so utterly unsuccessful it actually makes me laugh now. The limitations on the primary key and range keys alone make it just a very bad fit for this use case. AWS has a write up on how something like this could actually be achieved. I have never seen a better example of "shoehorning".
MongoDB then?
This could actually have worked. Still no actual relations, but Mongo has ways of making this work. Sadly, my brain just can not get used to the MongoDB query language: I found the defacto Node.js driver Mongoose a convoluted mess, especially the documentation. Also, I knew I was going to do a ton of aggregation on metrics (averages, percentiles etc.) and Mongo’s aggregation features were/are very minimal.
DynamoDB and also MongoDB are completely valid products. Just don’t use it for anything relational(ish). Mind blown.
Also, Postgres is pretty nimble, even with terabytes of data and high read/write traffic.
So Postgres it was. Onwards!
Single, multi-tenant database
Short interlude before we dive into the actual data model. How do we handle the partitioning of customers at the very highest implementation level now that we have chosen Postgres?
There are a couple of options out there:
- One tenant, one database: Each tenant its own database instance. 100% separation. If you expect either very high security requirements from customers or expect the need to scale out parts of your platform for specific customers, think Salesforce like size.
- One database, schema per customer: A single database, with a separate schema for each customer. Duplicating tables for each schema. This can make migrating especially heavy users to higher spec machines easy. It also is even more secure as you leverage the built-in security model of your DBMS.
- One database, one schema: Just one schema that holds all the tables and an “account ID” for each tenant. This is the model we chose for Checkly, as all of the above concerns are/were not applicable to Checkly. The expected usage patterns and storage needs are also not that massive
Accounts & users
Checkly and many other typical B2B focused SaaS are structured as follows:
- Users belong to an account, also sometimes called an organization.
- An account can have multiple users and users can switch between multiple accounts. This is specifically interesting if offering a product aimed at agencies or larger organizations where one customer can actually "own" multiple accounts.
- Accounts have settings, preferences and resources associated with it. They apply to each user linked to that account.
- Users can set personal preferences per linked account.
- Users can have specific access rights per account.
To achieve this, we use the following data schema:
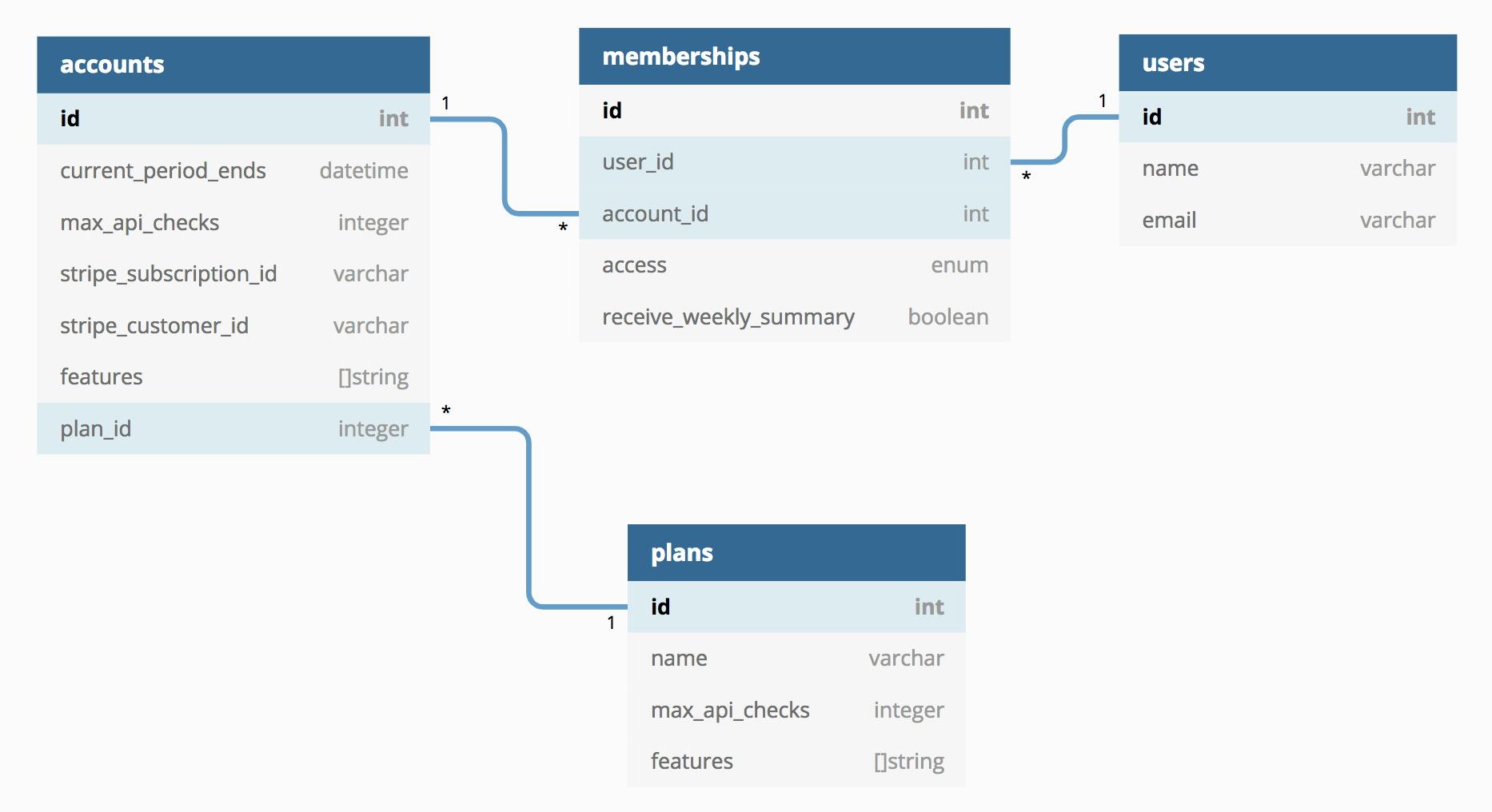
Let's go over each table and point out what's interesting:
1. Users
The users table is quite straightforward. It holds the basic details we gather either from social login (Google & Github in our case) or from email signup. Notice there is no password field. We use Auth0 for that.
2. Memberships
The memberships table models the many-to-many relation between users and their accounts. The most important bits are:
- Access control: The access field is an enum that holds one of the possible user roles as a string constant, i.e: READ_ONLY, READ_WRITE, ADMIN or OWNER. The actual enforcement of these roles is done in the API but that's a story for another time.
- Per-account user preferences: The receive_weekly_summary field is an example of a specific setting the user might want to toggle per account.
3. Accounts
This is where the meat is. The primary key of the accounts table is referenced as a foreign key in many, many other tables. Invoices, dashboards, team invites, etc. all reference the accounts table.
Besides being the root for almost all resources in the whole application, the accounts table has three main functions:
- Subscription & billing cycles: we need to keep track if payments are made in some way. In the example you can see the stripe_customer_id, stripe_subscription_id and the current_period_ends fields.
When a user signs up for a paid plan, we use Stripe webhooks to fill these fields. On each subsequent billing cycle our API receives another webhook call and we bump the current_period_ends date field.
Notice that if for any reason no money comes in, the date is never bumped. The rest of our code uses this field to check whether it should allow users to keep interacting with the product and whether it should do background jobs. - Plan limits: Each plan customers can subscribe to has volume limits associated with them. In our case these are things like amount of checks, amount of team mates, SMS messages sent per month. The upper limits for this are recorded in field like max_api_checks from the example.
These limits get set when subscribing and when changing to a higher/lower plan. More on that below. - Plan feature toggles: Plans can also have non-volume based differences. For example, people on our Developer plan do not have access to Setup & Teardown scripts. These are essentially feature toggles based on what plan you subscribe to.
To model this, we use the features field which is of the String Array type, a pretty nice feature in Postgres. It holds a set of string constants like SMS_ALERTS, SETUP_TEARDOWN and PROMETHEUS. Each constant is associated with a feature and we use them to enforce the limits in the API on the backend and show a nice hint to the user that a feature is only available after upgrading.
Funky tip 👉 We actually bump the current_period_ends date + some extra grace days. Would suck if the monitoring is down due to annoying but benign some card issue.
On plans & subscriptions
This might seem unintuitive, but there is a very weak relation between the plans table and the accounts table — you might have noticed the duplication of the max_api_checks and the features fields in each table.
Both these fields describe plan limits and we actively copy values from the plans table to the accounts table when an account is created. This makes tweaking specific customer requests a lot easier.
Want a custom plan that has slightly more API checks? We can do that. Just update the specific account row and adjust the monthly price in Stripe. Want to give access to a new feature to a small set of users? Just update the features array for just those account. Later roll it out to all customers. Who needs a complicated feature toggling framework?
So what actually is a subscription in this context? Good question, as it has no direct representation in this model. In the most literal sense, it is the invoice.payment_succeeded Stripe webhook coming in and telling us customer ID X with subscription ID Y has just paid.
Everything else is decoupled: the actual price per month / per year, the billing interval, what features you get and what volume limits apply. This decoupling then allows you to experiment more with price and the exact composition of your plans. Actually, the whole Checkly application has no "knowledge" of the pricing except for some markup on the https://checklyhq.com/pricing page.
banner image: Sadanobu Hasegawa (1809-1879). Original ca. 1860. Signature - Sadanobu. source