

We just released a big change on how often you can schedule your API and Browser checks. Together with our launching customer RMS — a leading property management solution — we looked at how we can catch hiccups and errors of mission-critical apps as early as possible and get better insights on uptime across the board.
First, the nitty gritty details:
- You can now run API checks up to every 10 seconds. Previously this was every 1 minute.
- You can now run Browser checks every 60 seconds. Previously this was every 5 minutes.
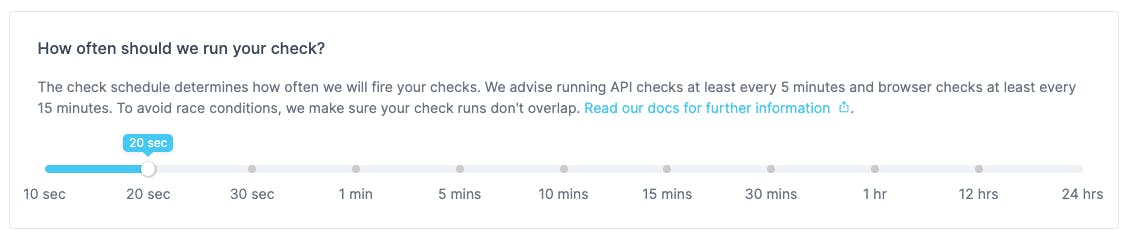
This feature is available to all customers on our metered pricing plan introduced this January and is visible in the Checkly app right now.
Ok, we got that out of the way. So, why does this matter?
How RMS uses high frequency checks for synthetic monitoring
Checkly checks your API or web apps at regular intervals. But those intervals were actually too long for some of our customers.
One example is RMS. RMS is headquartered in Australia and develops and supports online travel bookings, channel management, and front office systems serving over 6000 properties worldwide. RMS's online services are mission-critical for their clients, and they were looking for a solution to monitor the performance and uptime from different regions to proactively detect and fix any issues in real-time.
Rhys Allan, responsible for monitoring RMS’s cloud operations: "We are using Checkly's browser checks to ensure our login is working all the time and it ticks all the boxes, but we found that 5-minute check intervals were not thorough enough. We are now able to query our web apps every 60 seconds, which has given us greater insight into our performance and has detected minor disruptions that otherwise may have flown under the radar."
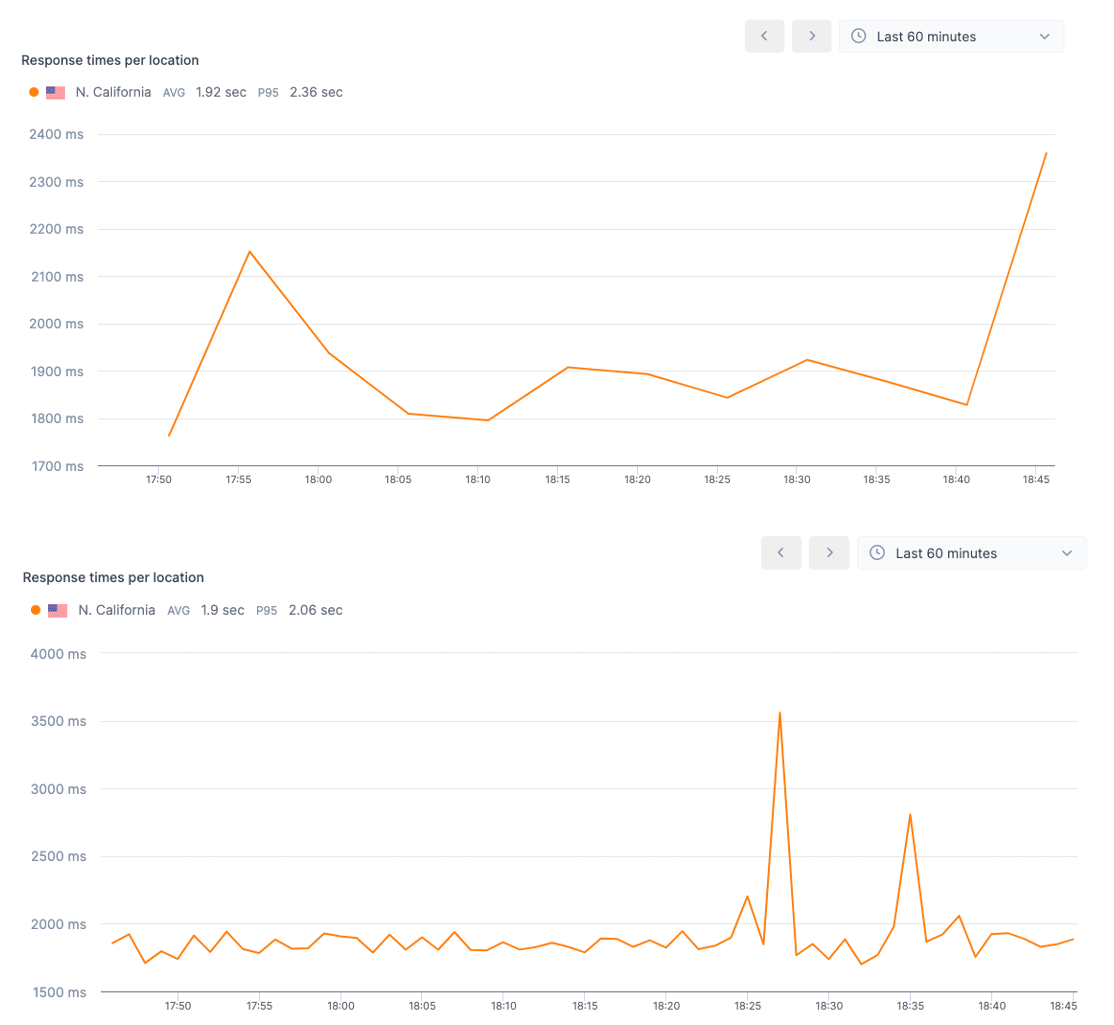
Comparison: Browser check run on 5-minute vs 1-minute interval
Benefits of running monitoring checks in short intervals
Rhys and the folks at RMS are a great example of why high(er) frequency checks are important. Let's boil it down.
Reduce downtime
Check intervals are your primary lever to stay ahead of issues and know about them before your users are impacted. Running checks at a higher frequency makes a significant difference in identifying and resolving problems earlier.
Capture and report micro disruptions correctly
Short downtimes or service degradations can stay undetected when the check intervals are too long, resulting in false negatives. Therefore it makes sense to match check intervals with your tolerance for service disruption.
On the other hand, you also don't want any outage — even if very brief — causing a significant hit on your SLO. Short check intervals will help to report the status more accurately, allowing you to reach high-availability goals.
More granular reporting and insights
This might be obvious, but more check runs per time interval will give you more granular data for reporting and troubleshooting. You get a better understanding of performance over time.
We hope you like the new options! If you want to share feedback or have questions how to use high-frequency checks when you are on an old pricing plan, reach us anytime via support@checklyhq.com.